In recent years, the field of generative AI, particularly Large Language Models (LLMs), has achieved tremendous advancements, transforming domains such as natural language understanding and creative content generation. Leading models like OpenAI’s GPT-4, Google’s Gemini, and Alibaba Cloud’s Qwen have raised the bar, demonstrating unprecedented levels of sophistication and capability. However, these breakthroughs have predominantly served high-resource languages like English, Chinese, Japanese, and Russian, leaving a significant gap in linguistic diversity. Recognizing this need, many countries are now focusing on developing their own national LLMs to customize these powerful technologies for their unique linguistic and cultural contexts.
ISSAI KAZ-LLM is designed to generate content in Kazakhstan’s three most relevant languages—Kazakh, Russian, and English, while also supporting Turkish as a representative of the broader Turkic family of languages. The initiative aims to benefit all sectors of Kazakhstani society and economy by addressing local needs through customized AI technology.
Crucially, the model also plays a role in preserving and promoting Kazakhstan’s cultural heritage by embedding ideological perspectives, historical contexts, and specialized knowledge reflective of the country’s unique identity. Through this effort, ISSAI KAZ-LLM shows how national AI projects can bridge linguistic gaps while contributing to the global AI landscape.
More than just a scientific project, ISSAI KAZ-LLM is actively contributing to the growth of skilled professionals in generative AI. By engaging in the full spectrum of data preparation, model training, and deployment, the project is equipping local talent with hands-on experience in developing and enhancing AI tools. The core development work was done by the local researchers of the ISSAI team.
To train a robust LLM, a substantial amount of high-quality data is essential. LLMs typically require billions of tokens—basic units of textual data, such as words or subwords. The final ISSAI KAZ-LLM training dataset comprises over 150 billion tokens across Kazakh, Russian, English, and Turkish, with 95% of the data collected and curated by ISSAI’s team. Tokens were sourced from public domains, including Kazakh websites, news articles, and online libraries. Additionally, high-quality English content was translated into Kazakh, and data from various organizations were integrated. In addition, the ISSAI team mastered the art of synthetic data generation for creating supervised finetuning datasets. A dedicated group of data scientists, called the “Token Factory,” ensured these data were cleaned and ready for model training.
ISSAI trained two versions of the model—8-billion (8B) and 70-billion (70B) parameter models—using eight NVIDIA DGX H100 nodes in the cloud. Both models are built on a variation of the Meta’s Llama architecture and aligned with state-of-the-art standards. We also created 4-bit quantized versions, significantly reducing the memory footprint and computational load, while still maintaining a relatively high level of accuracy. This makes these models particularly useful for deployment in resource-constrained environments, e.g., on notebook computers and workstations. A demo of the 70B model is available on our YouTube channel.
These models are now a crucial part of Kazakhstan’s soft digital infrastructure. The models can be used for non-commercial research and academic purposes, provided that appropriate attribution is given and no commercial activities are undertaken with them. Six models are available on our public Hugging Face repository:
To assess LLM performance, researchers typically use question-answering datasets that cover a broad range of topics. We adapted composite benchmarks, including datasets like ARC and MMLU, into Kazakh to evaluate the performance of the models across various tasks. Following the Hugging Face LLM Leaderboard, we also present our benchmarking suite to evaluate LLMs in Kazakh.
The trilingual (Kazakh, Russian, and English) benchmarking suite includes:
The 70B ISSAI KAZ-LLM model shows superior performance compared to open-source models in Kazakh and also demonstrates strong results in Russian and English, approaching the benchmarks of OpenAI’s models. Detailed scores for each dataset are provided in the accompanying figures.
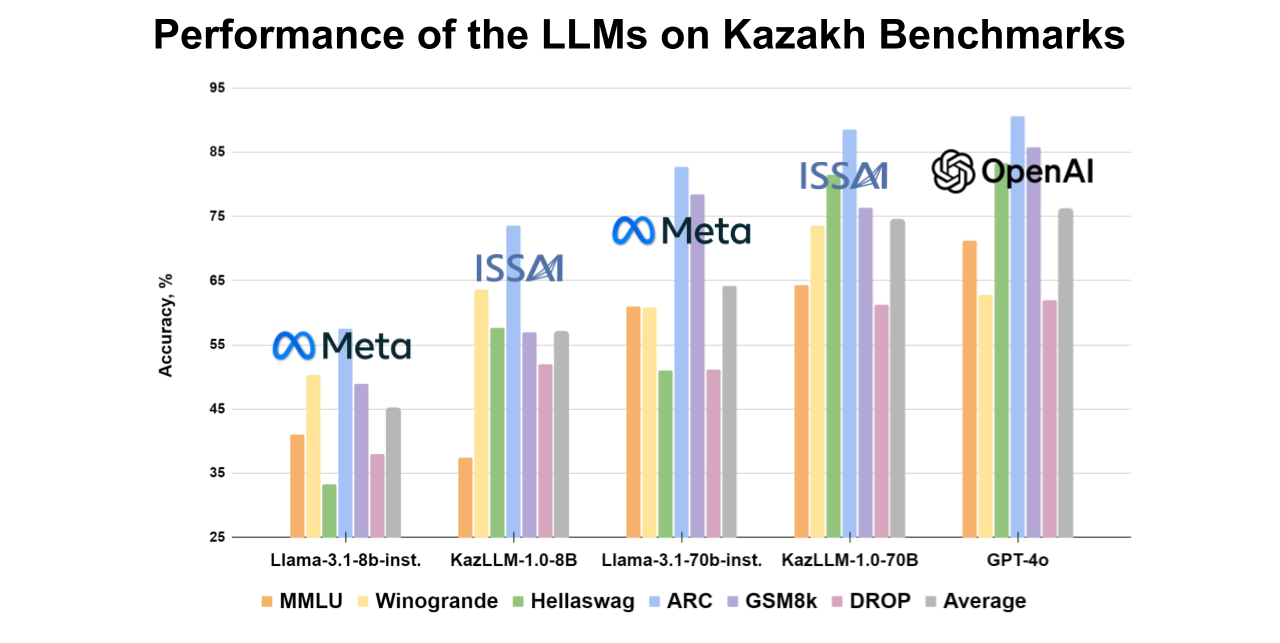
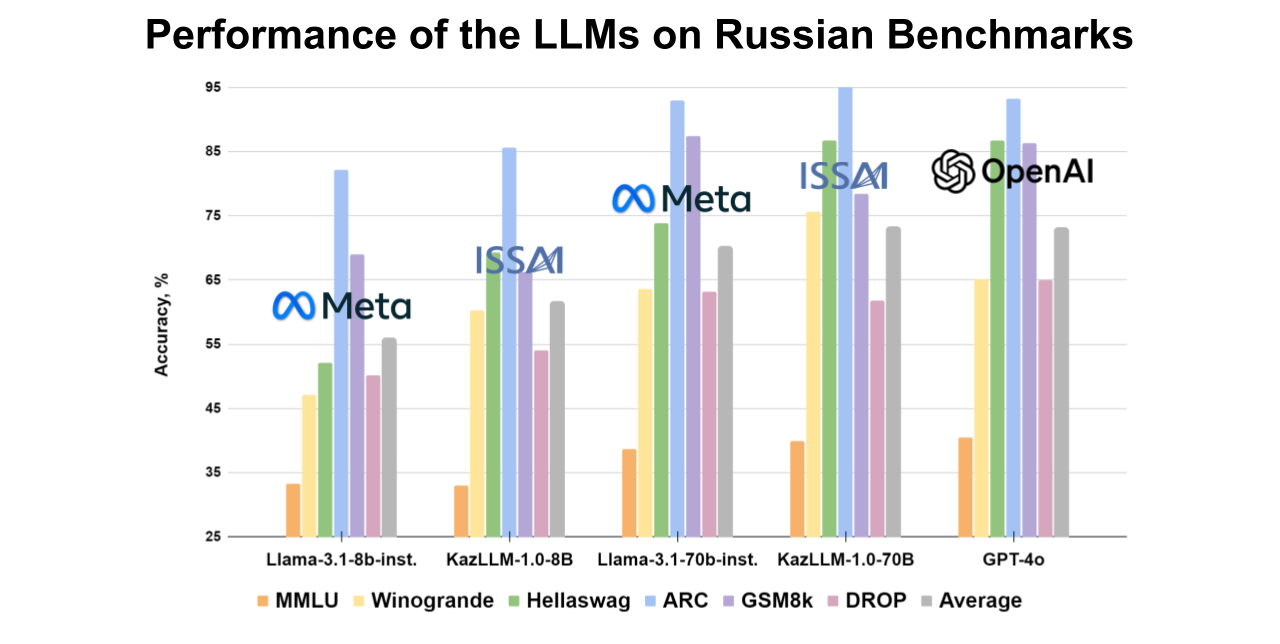
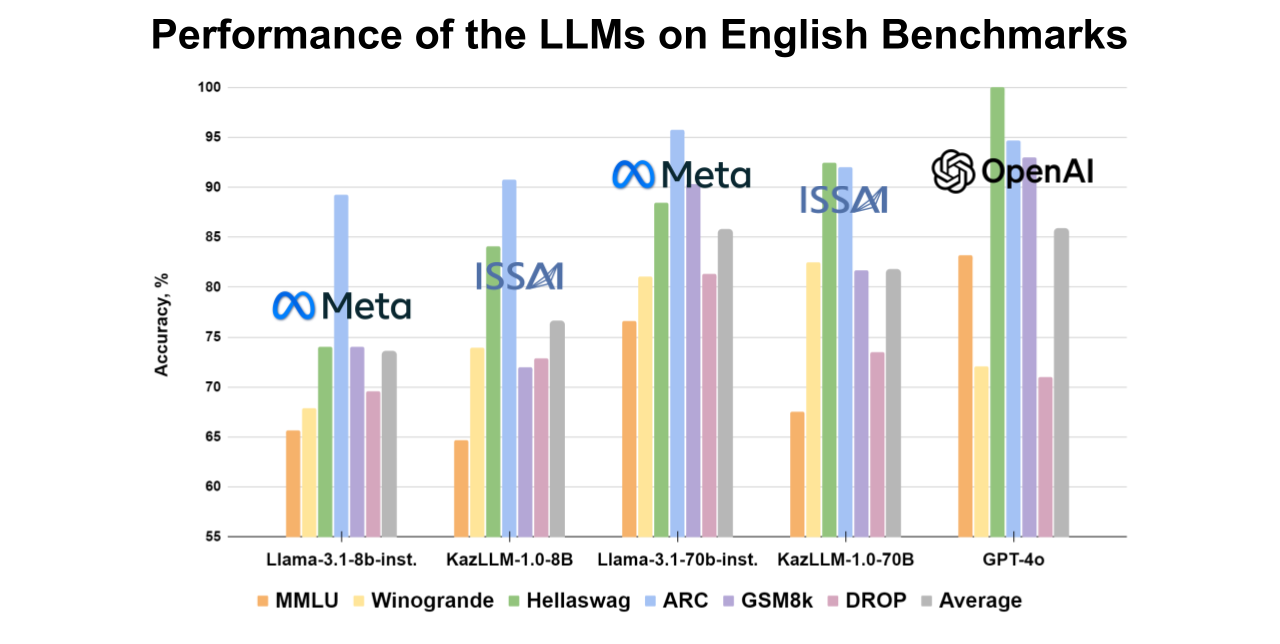
To adapt key datasets like MMLU and ARC to Kazakh, ISSAI collaborated with various institutions, including Al-Farabi Kazakh National University, Institute of Linguistics named after A. Baitursunuly, L. N. Gumilev Eurasian National University, Institute of Combustion Problems, M. Aitkhozhin Institute of Molecular Biology and Biochemistry, Institute of Mathematics and Mathematical Modeling, and Institute of Information and Computational Technologies. The remaining datasets were adapted by ISSAI’s linguistic team.
We present the ISSAI KAZ-LLM benchmarking suite, designed to stimulate the development and rigorous evaluation of generative AI tools in Kazakhstan and beyond. This comprehensive suite, which includes evaluation scripts and datasets, is now publicly available on our Hugging Face repository. The datasets have been carefully translated into Kazakh using both neural and human translation methods. By offering this suite, we aim to encourage broader AI experimentation and contribute to the global AI community, while supporting local language technologies and fostering innovation.
The ISSAI KAZ-LLM project was made possible through the financial support of the NU and NIS Foundation, Astana Hub, and QazCode (Beeline), whose sponsorship has been crucial to advancing this initiative. We are grateful for their confidence in this project, which was developed without reliance on public or taxpayer funds.

We sincerely appreciate the contributions of our scientific and administrative collaborators, including Ministry of Digital Development, Innovation and Aerospace Industry of the Republic of Kazakhstan, Ministry of Science and Higher Education of the Republic of Kazakhstan, National Information Technologies company (NIT JSC), National Scientific and Practical Center “Til-Qazyna” named after Shaysultan Shayakhmetov, Sustainable Innovation and Technology Foundation (SITF), Maksut Narikbayev University, and Al-Farabi Kazakh National University.

We also extend our gratitude to Nazarbayev University, a world-class research institution whose commitment to fostering innovation and providing an environment for intellectual growth has been instrumental to the success of this initiative.
For us, this is just the beginning of an exciting and challenging journey. This milestone demonstrates Kazakhstan’s potential to actively participate in the global AI race, utilizing the talents and intellect of its local workforce. As we continue securing the resources for research, our focus will remain on developing state-of-the-art AI models that serve the needs of the people of Kazakhstan.
Looking ahead, we plan to extend our work into next-generation language-vision models, further advancing AI capabilities. In addition, we’re exploring how to expand the model from its current capabilities in Kazakh and Turkish to other Turkic languages. By doing so, we aim to strengthen the ties between Turkic-speaking communities through technology and create opportunities for broader language inclusion.
We also aim to develop AI products and services that bring tangible benefits to the people of Kazakhstan and have a meaningful economic impact. By collaborating with partners, we seek to bridge the gap between academia and industry, driving innovation and accelerating the application of cutting-edge research to support growth and development in the local economy.
We welcome collaborations and additional support from other organizations. For media inquiries or collaboration proposals, please contact us at issai@nu.edu.kz