Генеративті жасанды интеллект (ЖИ) саласы, әсіресе үлкен тілдік модельдер (LLM) саласында, табиғи тілді түсіну және шығармашылық мазмұнды құру сияқты салаларды өзгерте отырып, соңғы жылдары орасан зор жетістіктерге жетті. OpenAI компаниясының GPT-4, Google компаниясының Gemini және Alibaba Cloud компаниясының Qwen сияқты жетекші модельдер жоғары күрделілік пен мүмкіндіктердің теңдессіз деңгейін көрсетіп, жаңа белестерді бағындырды. Алайда мұндай жетістіктер негізінен ағылшын, қытай, жапон және орыс сияқты ресурстары мол тілдерге бағытталып, тілдік әртүрлілік саласында айтарлықтай алшақтықты қалдырады. Бұл теңсіздікті түсініп, көптеген ел қазір ұлттық үлкен тілдік модельдерін дамытуға назар аударып, бұл технологияларды өздерінің тілдік және мәдени контекстіне бейімдеп жатыр.
ISSAI KAZ-LLM моделі Қазақстан үшін ең маңызды үш тілде (қазақ, орыс және ағылшын) контент жасауға арналған және түрік тілін түркі тілдері отбасына қатысты тіл ретінде қолдауды қамтиды. Бұл бастама Қазақстан қоғамының барлық секторына және экономикасына пайда әкелуге бағытталып, жергілікті қажеттіліктерді жеке ЖИ технологиялары арқылы қанағаттандырады.
Модель Қазақстанның мәдени мұрасын сақтау мен ілгерілетуде идеологиялық көзқарастарды, тарихи контекстерді және елдің бірегей ерекшелігін көрсететін арнайы білімдерді енгізу арқылы да маңызды рөл атқаратынын атап өткен жөн. Осы күш-жігер арқылы ISSAI KAZ-LLM ұлттық ЖИ жобалары ғаламдық ЖИ ортасының дамуына маңызды үлес қоса отырып, тілдік кедергілерді қалай жеңе алатынын көрсетеді.
ISSAI KAZ-LLM тек ғылыми жоба ғана емес, генеративті ЖИ саласындағы білікті мамандарды дамытуға маңызды үлес қосып жатыр. Жоба деректерді дайындаудан бастап, модельді оқыту мен оны енгізуге дейін — барлық процесті қамтиды, сондай-ақ жергілікті таланттарға ЖИ құралдарын әзірлеу және жетілдіру бойынша практикалық тәжірибе береді. Негізгі әзірлеу жұмыстары ISSAI командасының жергілікті зерттеушілері тарапынан жүргізілді.
Сенімді LLM-ді оқыту үшін сапалы деректердің елеулі көлемі қажет. LLM көбінесе миллиардтаған токенді — сөздер немесе сөз бөлшектері сияқты негізгі мәтін бірліктерді — талап етеді. ISSAI KAZ-LLM моделін оқыту үшін деректер жиынтығы 150 миллиардтан астам токенді қамтиды, оның ішінде қазақ, орыс, ағылшын және түрік тілдерінде, оның 95%-ы ISSAI командасы тарапынан жиналып, өңделген. Токендер ашық дереккөздерден алынды, оның ішінде қазақ тіліндегі веб-сайттар, жаңалық мақалалары және онлайн кітапханалар. Сонымен қатар, ағылшын тіліндегі жоғары сапалы контент қазақ тіліне аударылды, түрлі ұйымдардың деректері біріктірілді. ISSAI командасы нақты тар мақсаттар үшін алдын ала оқытылған LLM модельдерін бейімдеу мақсатында белгіленген деректер (supervised fine tuning) көмегімен деректер жиынтығын жасау үшін синтетикалық деректерді генерациялау әдістерін игерді. «Токен фабрикасы» деп аталатын арнайы жұмыс тобы осы деректердің тазартылуын және модельді оқытуға дайын болуын қамтамасыз етті.
ISSAI сегіз NVIDIA DGX H100 бұлттық серверін пайдалана отырып, 8 миллиард (8В) және 70 миллиард (70В) параметрі бар модельдің екі нұсқасын оқытты. Қос модель Meta компаниясының Llama архитектурасының нұсқасына сүйене отырып оқытылды және саладағы жетекші стандарттарға сәйкес жасалған. Сондай-ақ біз модельдердің 4 биттік квантизацияланған нұсқаларын жасадық; олар жадты тұтынуды және есептеу ресурстарын айтарлықтай азайтып, дәлдіктің жоғары деңгейін сақтайды. Бұл модель нұсқалары әсіресе ноутбуктер мен жұмыс станциялары сияқты ресурстары шектеулі орталарда қолдану үшін қолайлы. 70B параметрі бар модельдің демонстрациясы біздің YouTube арнамызда қолжетімді.
Бұл модельдер қазір Қазақстанның цифрлық инфрақұрылымының маңызды бөлігі болып табылады. Тиісті сілтеме жасалған кезде және коммерциялық мақсатта пайдаланылмаса, модельдер коммерциялық емес ғылыми және академиялық мақсаттарда пайдаланылуы мүмкін. Hugging Face платформасындағы ашық репозиторийімізде алты модель берілген:
LLM тиімділігін бағалау үшін зерттеушілер әдетте кең ауқымды тақырыптарды қамтитын сұрақ-жауап деректер жиынтықтарын пайдаланады. Моделдердің әртүрлі тапсырмалар бойынша тиімділігін бағалау үшін біздің команда ARC және MMLU сияқты кешенді бенчмарктарды қазақ тіліне бейімдеді. LLM Leaderboard Hugging Face үлгісін негізге ала отырып, біз қазақ тілінің үлкен тілдік модельдерін бағалау жинағының нұсқасын ұсынамыз.
Үштілді (қазақ, орыс және ағылшын) бенчмарк пакеті келесі деректер жинақтарынқамтиды:
70B параметрі бар ISSAI KAZ-LLM моделі қазақ тіліне арналған коды ашық басқа модельдермен салыстырғанда жоғары нәтижелер көрсетеді, сонымен қатар OpenAI модельдерінің өнімділігіне жақындай отырып, орыс және ағылшын тілдерінде құнды нәтижелер көрсетеді. Әрбір деректер жиынтығы үшін егжей-тегжейлі бағалар төменгі диаграммаларда көрсетілген.
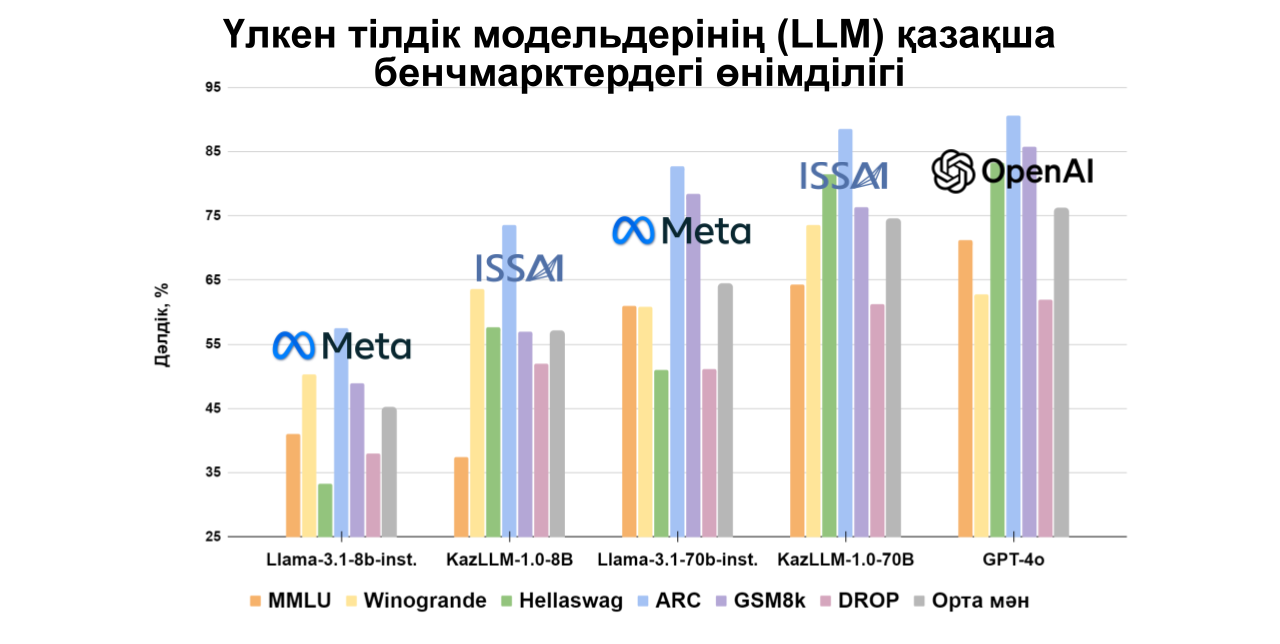
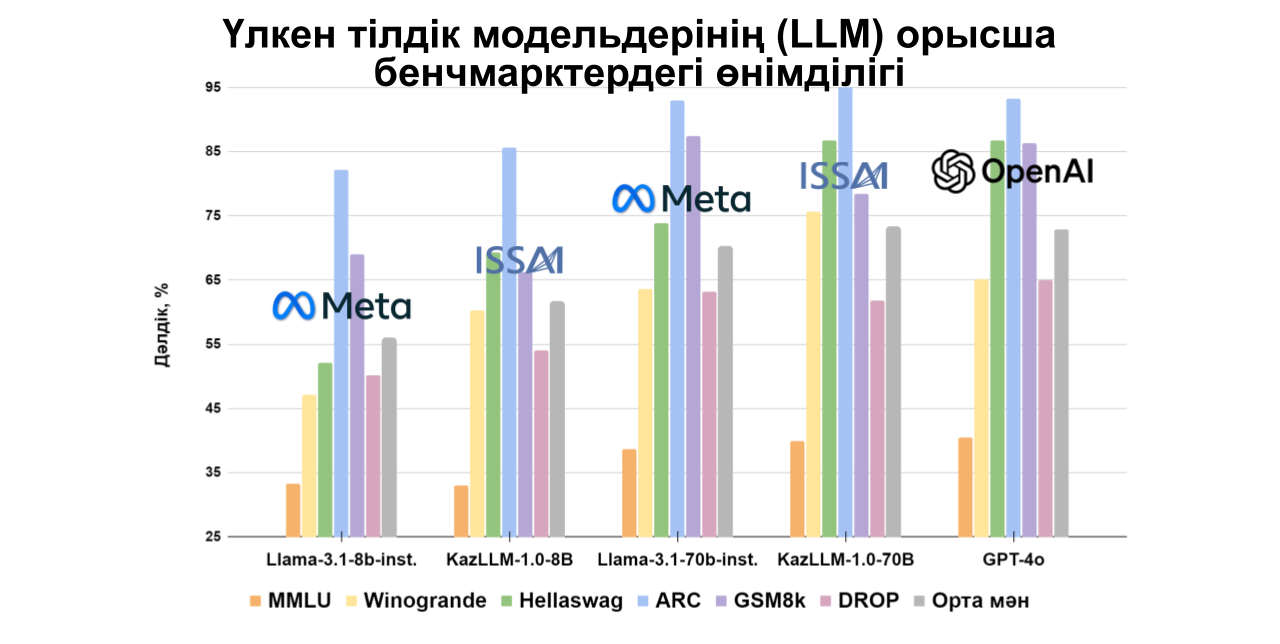
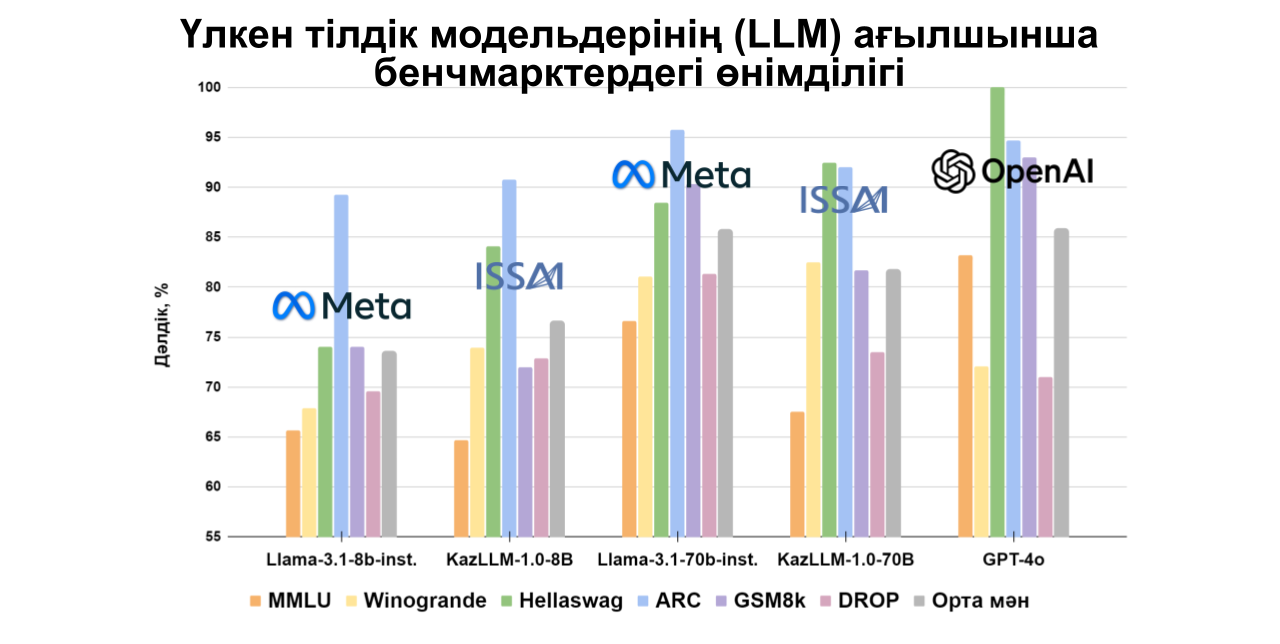
MMLU және ARC сияқты негізгі деректер жиынтықтарын қазақ тіліне бейімдеу мақсатында ISSAI бірнеше мекемемен, оның ішінде әл-Фараби атындағы Қазақ ұлттық университеті, А. Байтұрсынов атындағы Тіл білімі институты, Л. Н. Гумилев атындағы Еуразия ұлттық университеті, Жану проблемалары институты, М. А. Айтхожин атындағы Молекулалық биология және биохимия институты, Математика және математикалық модельдеу институты және Ақпараттық және есептеуіш технологиялар институты, ынтымақтастық орнатты. Қалған деректер жиынтықтарын ISSAI-дың лингвистер тобы бейімдеді.
Осылайша, біз Қазақстанда және оның шегінен тыс жерде генеративті ЖИ құралдарын әзірлеу мен бағалауды ынталандыруға арналған ISSAI KAZ-LLM салыстыру пакетін ұсынамыз. Бұл кешенді пакет деректер жиынтықтарын ғана емес, сондай-ақ модельдерді бағалау үшін скрипттерді де қамтиды. Пакет біздің Hugging Face ашық репозиторийімізде қолжетімді. Деректер жиынтықтары нейрондық желілер мен лингвистердің көмегімен қазақ тіліне мұқият аударылды. Осы пакетті ұсына отырып, біз ЖИ саласындағы зерттеулерді кеңейтуді, ғаламдық ЖИ қоғамдастығына үлес қосуды, жергілікті тіл технологияларын қолдауды және инновацияларды ынталандыруды көздейміз.
ISSAI KAZ-LLM жобасы НУ мен НЗМ даму қорының, Astana Hub және QazCode (Beeline) компаниясының қаржылық қолдауының арқасында жүзеге асты. Олардың демеушілігі бұл бастаманы алға жылжытуда маңызды рөл атқарды. Біз осы жобаға деген сенімдері үшін алғыс айтамыз. Жоба мемлекеттік бюджет немесе салық төлеушілердің қаражатынсыз әзірленді.

Біз ғылыми және әкімшілік серіктестерімізге, оның ішінде Қазақстан Республикасының Цифрлық даму, инновациялар және аэроғарыш өнеркәсібі министрлігі, Қазақстан Республикасының Ғылым және жоғары білім министрлігі, «Ұлттық ақпараттық технологиялар» АҚ (ҰИТ АҚ), «Тіл-Қазына» ұлттық ғылыми-практикалық орталығы, Тұрақты инновациялар мен технологиялар қоры (SITF), Мақсұт Нәрікбаев атындағы университет және әл-Фараби атындағы Қазақ ұлттық университеті, шын жүректен алғысымызды білдіреміз.

Сонымен қатар, әлемдік деңгейдегі зерттеу мекемесі Назарбаев Университетіне алғысымызды айтып, оның инновацияларды қолдауға және интеллектуалды өсу үшін ортаны қамтамасыз етуге деген міндеттемесі осы бастаманың табысты болуына шешуші рөл атқарды.
Бұл біз үшін тек қызықты әрі күрделі жолдың басы ғана. Бұл кезең Қазақстанның ЖИ саласындағы ғаламдық бәсекеге белсене қатысу үшін жергілікті мамандардың таланттары мен ақыл-ойын пайдалану мүмкіндігін көрсетті. Алдағы уақытта зерттеулер үшін қажетті қаражатты тарта отырып, біз Қазақстан халқына қажетті жоғары сапалы ЖИ модельдерін әзірлеуге назар аударатын боламыз.
Болашақта біз тіл мен бейнені біріктіретін келесі буындағы модельдерді әзірлеуді жоспарлап отырмыз, бұл ЖИ мүмкіндіктерін одан әрі жақсартуға мүмкіндік береді. Сондай-ақ, біз модельді казақ және түрік тілдерінде бар мүмкіндіктерден басқа түркі тілдеріне кеңейтудің мүмкіндіктерін зерттеп жатырмыз. Осылайша, біз түркі тілдес қоғамдар арасындағы байланысты нығайтуға, сондай-ақ тілдерді кеңінен қолдануға жағдай жасай аламыз.
Сонымен қатар, біз Қазақстан халқына құнды пайда әкелетін және экономикалық әсер ететін ЖИ өнімдері мен қызметтерін әзірлеуге ұмтыламыз. Әртүрлі технологиялық серіктестермен ынтымақтастықты орнатып, біз ғылым мен өнеркәсіп арасындағы алшақтықты жоюға, инновацияларды ынталандыруға және алдыңғы қатарлы ғылыми жетістіктерді экономиканы дамытуға қолдау көрсету үшін жедел енгізуге бағытталған боламыз.
Біз әрқашан ынтымақтастыққа ашықпыз және басқа компаниялар мен институттар тарапынан қосымша қолдау ұсыныстарын қабылдаймыз.
Жоба туралы қосымша ақпарат алу үшін, БАҚ сұраныстары немесе ынтымақтастық ұсыныстары бойынша issai@nu.edu.kz электронды поштаға хабарласуыңызды сұраймыз.