
Бұл материал Astana Plus редакциясы ұсынған сұрақтар негізінде дайындалды.
2026 жылғы 14 ақпан — Астана, Қазақстан — KazLLM моделі жөніндегі соңғы сұрақтарға байланысты, Ақылды жүйелер мен жасанды интеллект институты (ISSAI) Қазақстанның алғашқы үлкен тілдік моделі KazLLM туралы жаңа мәліметтер жариялады. Оның мақсаты, шығу тегі және елдің цифрлық болашағы үшін стратегиялық маңызы түсіндірілді.
– Елдер өз LLM-дерін не себепті дамытады?
Генеративті ЖИ, әсіресе үлкен тілдік модельдер (LLM), қазіргі таңда дүниежүзі бойынша стратегиялық маңызды технологиялық бағытқа айналды. LLM-дер тек зерттеу құралы емес, олар фундаменталды цифрлық инфрақұрылым болып табылады. Олар іздеу жүйелерінде, білім беру платформаларында, корпоративтік бағдарламаларда, мемлекеттік қызметтерде, ұлттық қауіпсіздік жүйелерінде және келесі буындағы өнімділік құралдарында қолданылады. Фундаменталды модельдерді дамытатын елдер өзінің болашақ цифрлық экожүйесін, инновациялық әлеуетін және ұзақ мерзімді экономикалық бәсекеге қабілеттілігін қалыптастырады.
Жаһандық инвестициялардың көлемі бұл стратегиялық маңыздылықты айқын көрсетеді. Ірі технологиялық компаниялар генеративті ЖИ-ге қыруар ресурстар бөледі. Мысалға, Microsoft OpenAI-ге 13 миллиард АҚШ долларынан астам инвестиция салған. Amazon Anthropic-ке 4 миллиардқа дейін қаржы жұмсады. Google өзінің Gemini модельдері мен ЖИ инфрақұрылымына қомақты қаржы салуды жалғастыруда. OpenAI де келесі жылдары есептеу инфрақұрылымы, деректер орталықтары және модельді оқытуға ондаған миллиард доллар жұмсауды жоспарлап отыр. Бұл инвестициялар жаһандық деңгейдегі инфрақұрылым және ғылыми-зерттеу міндеттемелерінің ауқымдылығын көрсетеді.
Дегенмен, LLM тек технологиялық прогресс үшін емес, технологиялық тәуелсіздік үшін де маңызды. Көптеген елдер шетелдік ЖИ жүйелеріне толықтай сену деректерді басқару, тілдік қамту, қауіпсіздік, экономикалық пайданы алу және нормотивтік талаптарды ұстану мәселелерінде стратегиялық тәуелділікті тудыратынын түсіне бастады.
Кесте 1-де көрсетілгендей, көптеген елдер өздерінің ұлттық немесе тәуелсіз модельдерін дамытуды көздеп отыр:
| Модель | Ел | Дамытушы / Институт | Негізгі ерекшелігі |
| Falcon | БАӘ | Technology Innovation Institute (TII) | Мемлекетпен қаржыландырылған; АҚШ-тың жетекші жүйелерімен бәсекелесе алатын алғашқы ашық бастапқы кодты модельдердің бірі. |
| WuDao 2.0 | Қытай | Beijing Academy of AI (BAAI) | 1.75 трлн. параметрлі; ұлттық жасанды интеллект бойынша өзін-өзі қамтамасыз ету стратегиясын қолдайды. |
| Fugaku-LLM | Жапония | RIKEN / Tokyo Tech / Fujitsu | Шетелдік бұлтқа тәуелді болмау үшін ұлттық суперкомпьютерде әзірленген. |
| TAIDE | Тайвань | National Science & Technology Council | Жергілікті деректердің қауіпсіздігін қамтамасыз ету және сыртқы саяси ықпалға тәуелділікті азайту үшін жасалған. |
| SEA-LION | Сингапур | AI Singapore | Оңтүстік-Шығыс Азия елдерінің тілдеріне бағытталған. |
| GPT-NL | Нидерланды | TNO / SURF / NFI | Ашық, GDPR сәйкес модель. |
| OpenGPT-X | Германия | Fraunhofer IAIS / Jülich | Gaia-X экожүйесі аясында ЕО деректерінің тәуелсіздігін насихаттайды. |
| GPT-SW3 | Швеция | AI Sweden / RISE / WASP | Солтүстік тілдерге арналған алғашқы ірі генеративті модель. |
| Poro | Финляндия | TurkuNLP / Silo AI / LUMI | ЕО-тың LUMI суперкомпьютерінде әзірленген; аз ресурсты тілдерді қолдайды. |
| MarIA | Испания | Barcelona Supercomputing Center | Ұлттық кітапхананың веб-архивтерін пайдалана отырып әзірленген. |
| ALLaM | Сауд Арабиясы | SDAIA | Vision 2030 стратегиясына сай араб тіліндегі модель. |
| GigaChat | Ресей | Sber | ChatGPT-дің жергілікті баламасы; жергілікті интернет заңдарына сәйкес келеді. |
| BharatGPT | Үндістан | IIT Bombay Consortium | 14+ үнді тілдері мен диалектілерін қолдайтын дауыстық жүйе. |
1-кесте. Таңдалған ұлттық үлкен тілдік модельдер және олардың тәуелсіздік бағытындағы ерекшеліктері
Жоғарыдағы үлгі көрсетіп тұрғандай, экономикасы жетекші елдер LLM-дерді аса маңызды инфрақұрылым ретінде қарастырады. Ұлттық модельдерді дамыту арқылы елдер: тілдік және мәдени ерекшеліктерді сақтай алады, деректер қауіпсіздігін қамтамасыз етеді, экономикалық пайданы өз экожүйесінде ұстап қалады, геосаяси тәуелділікті азайтады және жергілікті ЖИ таланттарын қалыптастырады.
Қысқаша айтқанда, ұлттық немесе тәуелсіз LLM жасау — бұл цифрлық тәуелсіздік, экономикалық тұрақтылық және жаһандық бәсекеге қабілеттілікке қатысты стратегиялық шешім.
– KazLLM дегеніміз не және ол не үшін жасалды?
Үлкен тілдік модель — бұл үлкен мәтіндік деректерде келесі сөзді болжауға үйретілген ЖИ технологиясы. Адам сұрақ қойғанда, ол контекстке сәйкес жауап береді. ChatGPT сияқты жүйелер осындай модельге негізделген.
Пайдалануға ыңғайлы аналогия: үлкен тілдік модельді қозғалтқыш ретінде қарастыруға болады. Қозғалтқыш – ол дайын көлік емес, бірақ барлық функцияны іске қосатын негізгі механизм. Сол қозғалтқыш әртүрлі көліктерді, мысалы SUV, жеңіл автокөлік, трактор немесе автобусты қуаттай алады. Сол сияқты KazLLM — ЖИ ассистенттері мен чат-боттардың негізгі компоненті. Мемлекеттік ассистенттер, корпоративтік чат-боттар немесе білім беру платформалары оның негізінде жасалуы мүмкін. Модель — қозғалтқыш, ал практикалық қызметтер жасап шығару үшін қосымша әзірлеу, деректер қорлары мен құралдармен ықпалдастыру, және ауқымды инфрақұрылым қажет. ISSAI-ға нақты осы қозғалтқышты жасау міндеті жүктелді. Оның айналасында соңғы пайдаланушы қосымшаларын немесе қызметтерін жасауға немесе іске қосуға біздің институт қатысқан жоқ.
– KazLLM-ді кім жасады және неге бұл жобаны қолға алды?
KazLLM-ді 2024 жылдың сәуір айынан бастап желтоқсан айына дейін Назарбаев Университетіндегі Ақылды жүйелер мен жасанды интеллект институты (ISSAI) жасап шығарды. Жоба машиналық оқыту, деректер талдау ғылымы және компьютерлік инженерия салаларындағы қазақстандық жас зерттеушілерден құралған командамен жүзеге асырылды. Жоба негізгі ұлттық серіктестермен бірлесіп жүзеге асырылды, олардың қатарында Жасанды интеллект және цифрлық даму министрлігі, Ғылым және жоғары білім министрлігі, «Ұлттық ақпараттық технологиялар» АҚ, «Тіл-Қазына» ұлттық ғылыми-практикалық орталығы, QazCode (Beeline), MIND Group (Maqsut Narikbayev University), сондай-ақ жетекші университеттер мен ғылыми-зерттеу институттары бар.
ISSAI-дің негізгі мақсаттарының бірі тек модель жасау ғана емес, ұлттық сараптамалық әлеуетті қалыптастыру болды. KazLLM әзірлеу жоғары сапалы деректер жиынтығын жинақтауды, оқыту үдерістерін жобалауды, ғылыми зерттеулер жүргізуді және ауқымды модельдерді әзірлеу бойынша практикалық тәжірибе жинақтауды талап етті. Бұл құзыреттер ұзақ мерзімді технологиялық тәуелсіздік үшін аса маңызды.
ISSAI KazLLM-нің екі нұсқасын әзірледі: жұмыс станциясы деңгейінде қолдануға арналған 8 миллиард параметрлі модель және деректер орталықтарында енгізуге бағытталған 70 миллиард параметрлі модель. Модель Llama 3.1 архитектурасына негізделді, себебі сол кезеңде ол әлемдегі ең мықты ашық бастапқы кодты архитектуралардың бірі болды.
Мысалы, 2024 жылғы желтоқсанда AI Singapore ұйымы ұсынған Оңтүстік-Шығыс Азияға бағытталған SEA-LION үлкен тілдік моделі де Llama тектес архитектураларға негізделген. SEA-LION жобасы ауқымды бағдарлама болып табылады және Сингапур бұл жобаға шамамен 52 миллион АҚШ долларын бөлді.
Көптеген елдерде генеративті ЖИ модельдерін әзірлеуде ірі технологиялық компаниялар көш бастап келеді (OpenAI ChatGPT, Alibaba Qwen, Meta LLaMA, Anthropic Claude, DeepSeekAI DeepSeek). Алайда, Қазақстанда жеке сектордың ғылыми-зерттеу жұмыстарына (R&D) жұмсайтын шығындарының ЖІӨ-дегі үлесі салыстырмалы түрде төмен, әрі мұндай қызмет түрлері әдетте жеке сектор тарапынан жүзеге асырылмайды. Сондықтан, Үкімет академиялық зерттеу институтына жүгінді.
KazLLM-ді әзірлеу барысында жеке телекоммуникациялық компания бізге оқыту процесін жүргізу үшін 8 NVIDIA DGX H100 тораптарына қолжетімділік берді, ал жеке қор команда жұмысына қажетті операциялық шығындарды қаржыландырды. Салыстыратын болсақ, Meta LLaMA моделін жасау кезінде 16 мыңнан астам DGX H100 графикалық процессорларын пайдаланып, 400-ден астам зерттеушіні тартты. Бұл KazLLM әлдеқайда шектеулі ресурстармен әзірленгенін көрсетеді.
– KazLLM-нің көрсеткіштері қандай?
Халықаралық тәжірибеде мұндай модельдер бенчмарк көрсеткіштері арқылы бағаланады. ISSAI KazLLM моделі тілдік түсіну, есеп шығару қабілеті, нақты деректерге негізделген білім және жалпы пайымдау дағдыларын жан-жақты бағалайтын кеңінен қолданылатын стандартты бенчмарктар негізінде тексерілді. Бенчмарктардың бір бөлігі қазақ тіліне бейімделді. Жарияланған KazLLM модельдері жиынтық көрсеткіш бойынша Llama моделінің сәйкес бастапқы нұсқаларынан жоғары нәтиже көрсетті. Жарияланған сәтте (2024 жылғы желтоқсан) 70B KazLLM моделі GPT-4o көрсеткіштеріне өте жақын нәтижеге қол жеткізді (төмендегі 2-кесте).
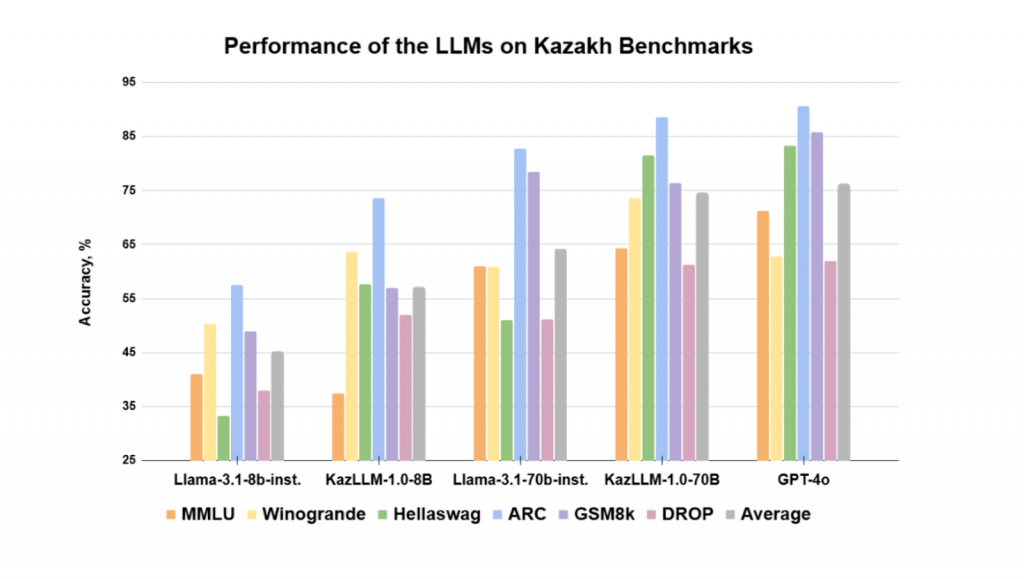
2-кесте. Қазақ тіліндегі бенчмарктар бойынша LLM модельдерінің өнімділігі
Алайда, жасанды интеллект – бұл үздіксіз бәсеке. Жаңа модельдер шамамен әр алты ай сайын ұсынылып отырады, сондықтан KazLLM-ді әрі қарай дамыту қажет. Біз 2024 жылғы желтоқсанда KazLLM-ді Astana Hub-қа тапсырғаннан кейін оны одан әрі жетілдіру туралы тапсырма алған жоқпыз.
KazLLM Қазақстанның генеративті жасанды интеллект саласында құзыреттілік қалыптастыруын қамтамасыз ету, ғылыми-зерттеу әлеуетін күшейту және осы жаһандық технологиялық трансформацияға қатысу үшін қажетті зияткерлік капиталды дамыту мақсатында құрылды.
Сонымен қатар, халықаралық көшбасшылар мен сарапшылар Қазақстанның өзінің ұлттық KazLLM моделін әзірлеу бастамасына назар аударды. Жасанды интеллект саласының ізашар зерттеушісі Янн Лекун 2025 жылғы Париж саммитінде KazLLM көрсеткіштерін атап өтті. Сондай-ақ, беделді GSMA Foundry Excellence Awards 2025 іс-шарасында KazLLM марапатқа ие болды.
– Қазақстанға неге өз тілдік моделі қажет?
ISSAI Қазақстанның жасанды интеллект саласындағы қажеттіліктеріне арналған жергілікті шешімдер жасауды тұрақты түрде қолдап келеді. Дегенмен, KazLLM-ді құру туралы ресми сұраныс үкімет тарапынан түсті. Жасанды интеллект технологиялары қоғамдық қызметтерге, бизнес операцияларына және ақпаратқа қолжетімділікке барған сайын әсер етіп жатқандықтан, тек шетелдік шешімдерге сену стратегиялық тәуелділікті тудыратыны анық болды. Жергілікті модельді дамыту Қазақстанға осы технологияның негізін түсінуге және оны бейімдеуге мүмкіндік береді.
– Көптеген адамдар KazLLM-ді ChatGPT-пен салыстырады. Негізгі айырмашылығы қандай?
ChatGPT — бұл толыққанды өнім және қызмет көрсету экожүйесі. Ол бірнеше нұсқалы үлкен тілдік модельдерді, ақылды маршрутизация жүйелерін, веб іздеу мүмкіндіктерін, дерекқорларды, қауіпсіздік және модерация қабаттарын біріктіреді және жаһандық деректер орталықтарында кеңінен орналастырылған. Модель пайдаланушы кері байланысы мен жасанды интеллект зерттеулеріндегі жетістіктер негізінде үздіксіз жаңартылып отырады. Ең маңыздысы, оны қолдау үшін өте қомақты қаржылық инвестициялар бөлінеді. Мысалы, OpenAI-дың жылдық операциялық және инфрақұрылым шығындары шамамен 1,4 триллион долларға жетеді деп күтілуде, бұл жүйелерді оқыту және қолдау үшін қажетті ауқымды көрсетеді. Осындай қаржыландыру деңгейі модельді үнемі жетілдіруді және оны жаһандық деңгейде орналастыруды қамтамасыз етеді.
KazLLM, керісінше, фундаменталды модель болып табылады. Ол жасанды интеллекттің негізгі қозғалтқышы, бірақ дайын жаһандық өнім емес. ChatGPT-ге ұқсас жүйе болу үшін оған іздеу құралдары мен дерекқорларды ықпалдастыру, пайдаланушыға арналған платформа жасау, үздіксіз қайта оқыту, қауіпсіздік жүйелерін енгізу және ірі деректер орталықтарында орналастыру қажет болады.
Осылайша, жоғарыда аталған барлық дамытулар қомақты және тұрақты қаржылық инвестицияны талап етеді. Қарапайым мысал: KazLLM — бұл қозғалтқыш болса, ChatGPT — толық жинақталған, жыл сайынғы жаңартулар мен техникалық қызмет көрсету арқылы әлемдік деңгейде жұмыс істейтін дайын көлік.
– KazLLM-ді кім пайдалана алады?
KazLLM кеңінен зерттеу мақсатында қолданылды, бұл ашық репозиторийлерден жүктеулерде көрініс табады (https://huggingface.co/issai). Зерттеушілер мен әзірлеушілер оны әрі қарайғы жаңалықтар мен инновациялар үшін негіз ретінде тәжірибеде қолданады. 2024 жылғы желтоқсанда Astana Hub-қа айрықшалығы жоқ лицензия берілгендіктен, қазіргі уақытта оның операциялық немесе коммерциялық қолданылуы туралы бізде ақпарат жоқ.
– Бұл модельдер біздің күнделікті өмірімізді қалай жеңілдетуі мүмкін?
Практикалық мысал ретінде мемлекеттік қызметтермен өзара әрекеттесуді айтуға болады. Күрделі веб-сайттар арқылы іздеудің орнына, азамат өз сұрағын табиғи тілде сипаттап, құрылымдық нұсқаулық ала алады (мысалы, AI чат-бот арқылы). Білім беру саласында студенттерге ғылыми тұжырымдамаларды олардың түсіну деңгейіне сай қазақ тілінде түсіндіріп беру мүмкіндігі туындайды. Бизнесте компаниялар құжаттарды автоматты түрде дайындау немесе ішкі білімді басқару жүйелерін оңтайландыруға мүмкіндік алады. Осындай қолданбалар генеративті жасанды интеллекттің қолжетімділікті және тиімділікті арттыра алатынын көрсетеді.
– Неліктен жасанды интеллекттің қазақ тілін және жергілікті контекстті түсінуі маңызды?
Көптеген жаһандық модельдер негізінен ағылшын тіліндегі деректерге негізделіп дайындалады. Сол себепті қазақ тіліндегі мазмұн және мәдени контекст жеткілікті деңгейде ескерілмейді. Бұл жергілікті ақиқатты дәл түсінбеуге немесе үстіртін түсінуге әкелуі мүмкін. Сонымен қатар, тек шетелдік ЖИ жүйелеріне тәуелділік техникалық және стратегиялық тәуелділікті тудырады. Цифрлық егемендік технологиялық жүйелерді түсіну, бейімдеу және қажет болған жағдайда тәуелсіз дамыту қабілетін талап етеді. Сондай-ақ, модельдер жергілікті дәстүрлер, тарих және мәдениет туралы сенімді және дұрыс ақпарат бере алу маңызды.
– KazLLM және тілдік модельдер туралы ең жиі кездесетін қате түсінік қандай?
Бәсекеге қабілетті болу үшін тұрақты инвестициялар мен зерттеулер қажет. Сондықтан. технологиялық дамыған елдер ЖІӨ-нің үлкен бөлігін ғылыми-зерттеу жұмыстарына (R&D) бөледі (Израиль, Оңтүстік Корея, Швеция, АҚШ және т.б.), ал тез дамып келе жатқан орташа табысты елдерде де ЖІӨ-нің 1%-дан астамы R&D-ге жұмсалады (Қазақстанда шамамен 0,2%).
Кең таралған қате түсінік — модель бір рет шығарылған соң ол соңғы немесе тұрақты жетістік болып есептеледі деп ойлау. Шындығында, генеративті жасанды интеллект өте тез дамиды. Жаңа архитектуралар мен оқыту әдістері жиі пайда болады. KazLLM енгізілгеннен бері көптеген жетістіктерге қол жеткізілді (эксперттік архитектураларды біріктіру, пайымдау модельдері, мультимодальді LLM, көптокенді болжамдар және т.б.). Соңғы 13 ай ішінде OpenAI шамамен 5 негізгі GPT нұсқасын шығарды (GPT-4.1, 4.5, GPT-5 сериялары), ал Alibaba-ның Qwen моделі шамамен 7 негізгі нұсқасын жариялады (Qwen2.5 және Qwen3 сериялары). Зерттеу және дамыту тобы әрдайым дерекқорды жаңартып, модельді соңғы архитектурамен қайта баптап, жаңа нұсқаларды шығарып отыруы қажет. Бұл автомобиль индустриясына ұқсас, бірақ уақыт ауқымы әлдеқайда қысқа.
Біздің өңірде генеративті ЖИ-ге жеке сектор инвестициясының ең айқын мысалдарының бірі — Ресей Федерациясындағы Sberbank жұмысы. Банк өзінің жасанды интеллект модельдері мен құралдарын жасап, енгізіп отыр. Sberbank-тың генеративті AI өнімдері, мысалы, GigaChat, жаһандық үлкен тілдік модельдермен бәсекелесуге арналған және әртүрлі салаларда енгізіліп жатыр, олардың мүмкіндіктерін кеңейту және қолжетімділікті арттыру, соның ішінде GigaChat 3 Ultra Preview сияқты жетілдірілген модельдерді ашық бастапқы кодпен шығару жоспарлануда.
Sberbank сондай-ақ ЖИ саласына белсенді инвестициялық жоспарларын жариялап, болашақта айтарлықтай шығындар бөлуді мақсат етіп, технологиялық ізін түрлендіру және осы технологиялардан елеулі пайда табу ниетін білдірді.
Бұл тәжірибені ескере отырып және Қазақстанның банк секторының қаржылық тұрақтылығын қарастыра отырып, Қазақстандық қаржы институттары жергілікті генеративті ЖИ дамытуға, әсіресе жергілікті жағдайға бейімделіп, кеңейтілетін ашық бастапқы кодтағы модельдер арқылы инвестиция салуға айқын мүмкіндікке ие. Мұндай стратегиялық инвестиция тек технологиялық егемендікті қолдаумен шектелмей, елдің цифрлық экономикасында бәсекеге қабілеттілікті және инновацияны арттыруға да мүмкіндік береді.
– Қарапайым қолданушылар KazLLM-мен күнделікті өмірде әрекеттесе ала ма?
Иә, алайда үлкен модельдер үшін айтарлықтай есептеу инфрақұрылымы қажет. Оларды ауқымды түрде оқыту және орналастыру жоғары өнімді деректер орталықтарына тәуелді. Әлемде мұндай инфрақұрылымды құруға қарқынды бәсекелестік бар. Ауқымды орналастырусыз негізгі модель көпшілік пайдаланушыларға тиімді қызмет көрсете алмайды.
Мүмкін, осы модельге негізделген жасанды интеллект агенттері немесе чат-боттар Қазақстандағы жаңа суперкомпьютерлерде орналастырылуы мүмкін (AlemCloud, Al-Farabium кластерлері). Егер жаңа суперкомпьютерлер басқа маңызды қызметтер мен модельдерге толтырылмаған болса, KazLLM сияқты модельдер жалпыға қолжетімді етіліп, пайдаланушылардан кері байланыс жинауға мүмкіндік тууы мүмкін.
– Бүгінгі күні адамдар KazLLM-ді іс жүзінде көре ала ма?
2024 жылғы желтоқсанның соңында Назарбаев Университеті Astana Hub-қа айрықшалығы жоқ лицензия берді. Модельді орналастыру инфрақұрылым мен лицензия иегерінің операциялық шешімдеріне тәуелді. Қазіргі қолданылуы жөнінде бізде нақты ақпарат жоқ.
– “Галлюцинациялар” мен қателер мәселесі қалай шешіледі?
Барлық генеративті модельдер кейде дәл емес жауаптар бере алады. Мұндай қателерді азайту үшін дерекқордан ақпарат алу, веб іздеу, қорғау механизмдері және пайдаланушы кері байланысы сияқты тексеру құралдарын біріктіру қажет. Жеке модельдің өзі сенімділікті қамтамасыз етпейді. Жауапкершілігі бар орналастыру үшін толыққанды өнім жасау керек.
Генеративті ЖИ модельдері пайдаланушыларға енгізілгеннен кейін олардың әрекеті маңызды ақпарат көзіне айналады. Пайдаланушылар қойған әр сұрақ, атқарылған әр тапсырма немесе бағаланған әр жауап модельдің нақты өмірдегі тиімділігін көрсететін құнды дерек береді. Бұл өзара әрекет үнемі бақыланып, талданып, өнімді дамыту циклінде қателердің үлгілерін, білімдегі кемшіліктерді немесе модельдің пайымдауындағы жетіспеушіліктерді анықтау үшін қолданылады.
Осы модельдерге негізделген коммерциялық қызметтер кері байланыс арқылы модель мінез-құлқын жаңартып, дәлдігін арттырып, пайдаланушы тәжірибесін жақсартады. Мысалы, кейбір компоненттерді қайта оқыту, параметрлерді баптау, сұрау құрылымдарын жетілдіру немесе дерекқордан ақпарат алу және веб іздеуді қосу сияқты түзетулер енгізілуі мүмкін.
Алайда, бұл процесс еңбекқорлықты талап етеді және адам, есептеу және қаржылық ресурстарды қажет етеді. Инженерлер, деректер ғалымдары, дерек кураторлары және өнім менеджерлерінен тұратын білікті командалар пайдаланушылардың әрекетін қарап, қателерді жіктеп, жақсартуларды енгізіп, жаңартуларды іске асыруы тиіс. Сонымен қатар, адамның қадағалауы модельдің этикалық және қауіпсіз қолданылуын қамтамасыз етеді, нормативтік талаптарға сәйкестікті сақтайды және нәтижелерді бизнес пен қоғам стандарттарына сәйкес келтіреді. Модельдер арнайы адам араласуынсыз жүзеге асырылса, коммерциялық қызмет үшін қажетті сапаны қамтамасыз ете отырып, сенімді түрде дами алмайды.
– Мұндай технологиялар білім беру мен еңбек нарығына қалай әсер етеді?
Генеративті ЖИ көптеген кәсіптерді қайта құрып, күнделікті когнитивтік тапсырмаларды автоматтандырады. Ішкі сараптамалық біліктілікті дамытқан елдер экономикалық тұрғыдан көбірек пайда көре алады. Ал толығымен сыртқы жүйелерге тәуелді елдер үлкен мәселелерге тап болуы мүмкін.
– Тілдік модельдерді қолдану қауіпті болатын салалар бар ма?
Ұзақ мерзімді және орта мерзімді тәуекелдер бар. Танымал сарапшылар, оның ішінде Тьюринг сыйлығының лауреаты Джеффри Хинтон, дамыған ЖИ жүйелерінен болуы мүмкін экзистенциалды қауіптер туралы ескерткен. Тарихшы Юваль Ной Харари де ЖИ атом бомбаларынан қауіпті болуы мүмкін екенін атап өтті, өйткені дамыған ЖИ дербес әрекет етіп, адам бақылауынсыз шешім қабылдай алады. Ұзақ мерзімді экзистенциалды және әлеуметтік тәуекелдерге қатаң басқару және қадағалау қажет болса, орта мерзімді тәуекелдерге deepfake, жалған ақпарат, киберқылмыс және ең бастысы технологиялық тоқырау жатады. ЖИ технологияларын жауапкершілікпен дамытпайтын елдер мен институттар бәсекеге қабілеттілігін, технологиялық тәуелсіздігін және стратегиялық ықпалын жоғалтуы мүмкін.
– Қарапайым азаматтар қалай үлес қоса алады?
Қазіргі ЖИ парадигмасы – машиналық оқыту. Осы парадигмада модельдер деректерден үйренеді. Егер қазақстандық азамат қазақ тілінде қоғамдық деректер жасаса (мысалы, Wikipedia мақаласы), жергілікті және жаһандық ЖИ модельдері осы деректерді пайдаланып оқытылады және Қазақстан мен қазақ тілі туралы көбірек біледі. Сондықтан, көмек көрсеткісі келген қарапайым азамат Қазақстанға қатысты мазмұн жасау арқылы үлес қоса алады.Екіншіден, көптеген технологиялық алыптар модельдерді төмен немесе тегін бағамен ұсынады, олардың ниеті қайырымдылық емес, олар кері байланыс пен нақты қолдану мысалдарын жинауды мақсат етеді. Сондықтан, жергілікті ЖИ модельдерін (Oylan, MangiSoz) пайдаланып, кері байланыс беру олардың дамуына айтарлықтай үлес қосар еді.