В последние годы область генеративного искусственного интеллекта (ИИ), особенно в области больших языковых моделей (LLM), достигла огромных успехов, трансформировав такие области, как понимание естественного языка и создание креативного контента. Ведущие модели, такие как GPT-4 от OpenAI, Gemini от Google и Qwen от Alibaba Cloud, подняли планку, демонстрируя беспрецедентные уровни сложности и возможностей. Однако подобные достижения в основном охватывают языки с высоким уровнем доступности, такие как английский, китайский, японский и русский, оставляя значительный разрыв в языковом разнообразии. Осознавая это неравенство, многие страны в настоящее время разрабатывают собственные национальные LLM, адаптируя данные технологии к своим уникальным языковым и культурным контекстам.
Модель ISSAI KAZ-LLM предназначена для создания контента на трех наиболее актуальных языках для Казахстана: казахском, русском и английском, с дополнительной поддержкой турецкого языка как представителя тюркской языковой группы. Эта инициатива направлена на пользу всем секторам казахстанского общества и экономики, удовлетворяя потребности с помощью индивидуализированных ИИ-технологий.
Важно отметить, что модель также играет роль в сохранении и продвижении культурного наследия Казахстана, внедряя идеологические перспективы, исторические контексты и специализированные знания, отражающие уникальную идентичность страны. Благодаря этим усилиям, ISSAI KAZ-LLM показывает, как национальные проекты ИИ могут преодолевать языковые барьеры, одновременно внося значимый вклад в развитие глобальной ИИ-среды.
ISSAI KAZ-LLM представляет собой не только научный проект, но и важный вклад в развитие квалифицированных специалистов в области генеративного ИИ. Проект охватывает весь процесс — от подготовки данных и обучения модели до ее внедрения, предоставляя местным талантам практический опыт в разработке и совершенствовании ИИ-инструментов. Основная работа по разработке была выполнена отечественными исследователями из команды ISSAI.
Для обучения надежной LLM требуется значительное количество высококачественных данных. LLM обычно требуют миллиарды токенов — базовых единиц текстовых данных, таких как слова или подслова. Окончательный набор данных для обучения ISSAI KAZ-LLM включает более 150 миллиардов токенов на казахском, русском, английском и турецком языках, 95% которых были собраны и подготовлены командой ISSAI. Токены были получены из общедоступных источников, включая казахские веб-сайты, новостные статьи и онлайн-библиотеки. Кроме того, высококачественный контент на английском языке был переведен на казахский язык. Были также использованы данные, предоставленные различными организациями. Командой ISSAI были освоены методы синтетической генерации данных для создания наборов данных для адаптации предварительно обученных LLM под конкретные узкие задачи при помощи размеченных данных (supervised fine tuning). Специальная рабочая группа под названием «Фабрика токенов», обеспечивала очистку этих данных и их готовность к обучению модели.
ISSAI обучил две версии модели — с 8 миллиардами (8B) и 70 миллиардами (70B) параметров, используя восемь облачных серверов NVIDIA DGX H100. Обе модели основаны на варианте архитектуры Llama от Meta и соответствуют передовым стандартам. Нами также были созданы 4-битные квантизированные версии моделей, что значительно сократило потребление памяти и вычислительные ресурсы, при этом сохранив достаточно высокий уровень точности. Данные версии моделей особенно подходят для развертывания в средах с ограниченными ресурсами, таких как ноутбуки и рабочие станции. Демо-версия модели с 70B параметрами доступна на нашем YouTube-канале.
Данные модели теперь являются важной частью цифровой инфраструктуры Казахстана. Модели могут быть использованы для некоммерческих научных и академических целей, при условии, что предоставляется соответствующая ссылка на авторство и не применяются в рамках коммерческой деятельности. Шесть моделей доступны в нашем публичном репозитории на Hugging Face:
Для оценки производительности LLM обычно используются наборы данных с вопросно-ответными парами (бенчмарки), охватывающие широкий спектр тем. Для оценки производительности моделей по различным задачам на казахском языке наша команда адаптировала комплексные бенчмарки, включая такие наборы данных как ARC и MMLU. Следуя примеру LLM Leaderboard Hugging Face, мы представляем нашу версию набора для оценки LLM на казахском языке.
Трехъязычный (казахский, русский и английский) бенчмарк-пакет включает в себя:
Модель ISSAI KAZ-LLM с 70 миллиардами параметров показывает высокие результаты по сравнению с другими моделями с открытым исходным кодом на казахском языке, а также демонстрирует сильные результаты на русском и английском языках, приближаясь к показателям моделей OpenAI. Подробные оценки для каждого набора данных представлены в графиках ниже.
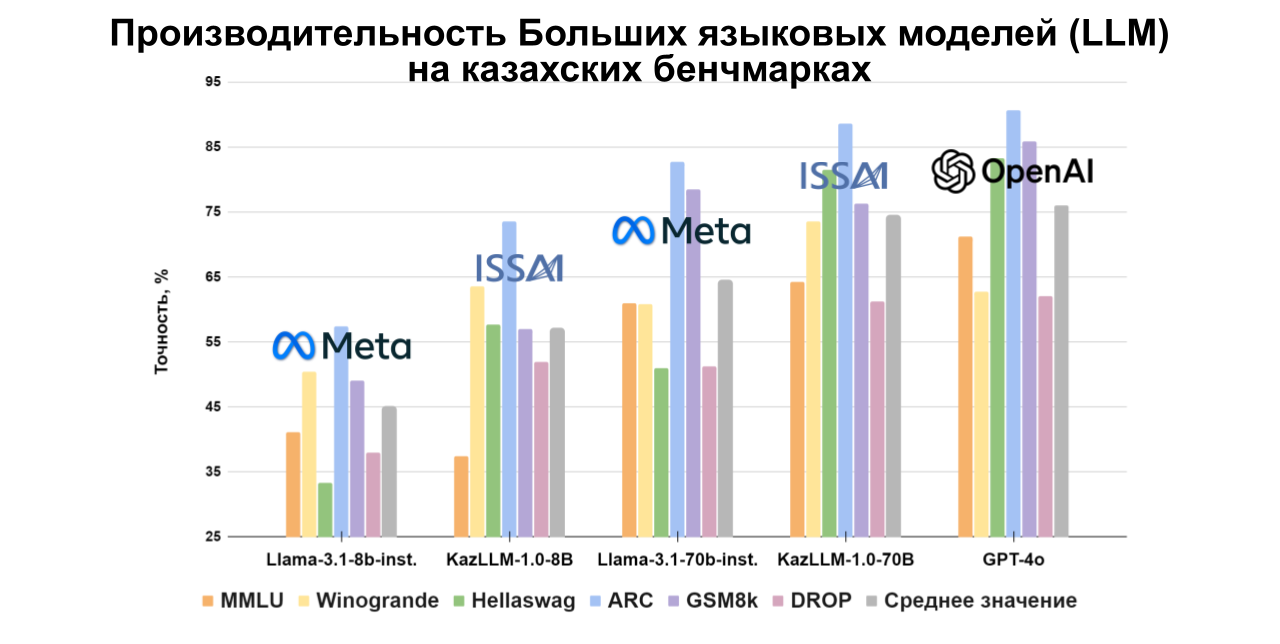
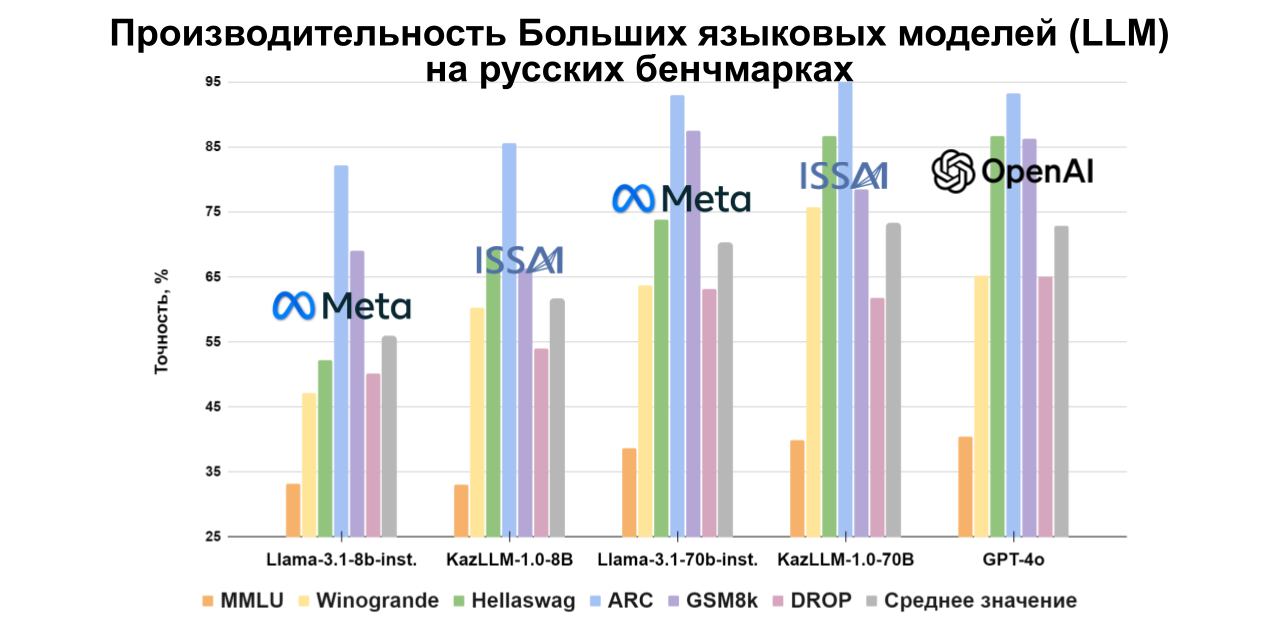
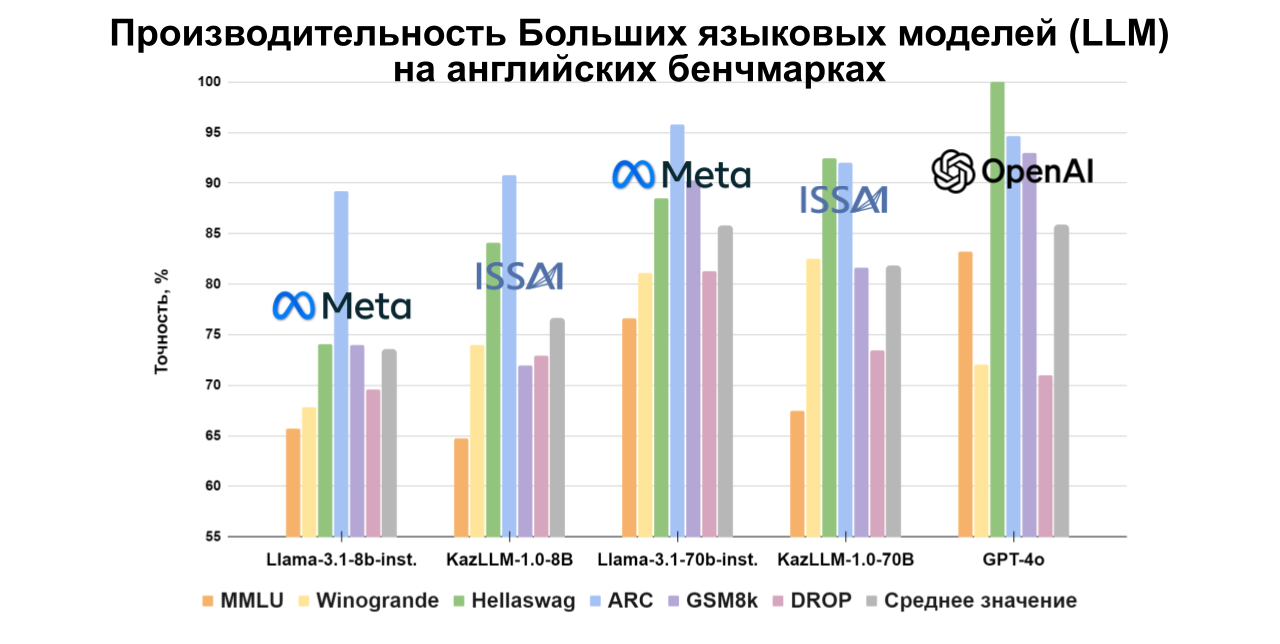
Для адаптации ключевых наборов данных, таких как MMLU и ARC, на казахский язык ISSAI сотрудничал с различными учреждениями, включая Казахский национальный университет имени Аль-Фараби, Институт языкознания имени А. Байтурсынова, ЕНУ им. Л. Н. Гумилева, Институт проблем горения, Институт молекулярной биологии и биохимии им. М. А. Айтхожина, Институт математики и математического моделирования и Институт информационных и вычислительных технологий. Остальные наборы данных были адаптированы командой лингвистов ISSAI.
Таким образом, мы выкладываем пакет для сравнительного анализа ISSAI KAZ-LLM, который создан для стимулирования разработки и тщательной оценки инструментов генеративного ИИ в Казахстане и за его пределами. Этот комплексный пакет включает в себя не только наборы данных, но также скрипты для оценки моделей. Пакет находится в открытом доступе в нашем репозитории на Hugging Face. Наборы данных были тщательно переведены на казахский язык с использованием как машинного перевода (нейронные сети), так и при помощи лингвистов. Предоставляя этот набор инструментов, мы стремимся к стимулированию разнообразных экспериментов с ИИ, тем самым внося вклад в мировое сообщество ИИ, а также поддерживая технологии на локальных языках и развивая инновации.
Проект ISSAI KAZ-LLM стал возможен благодаря финансовой поддержке фонда развития NU и NIS, Astana Hub и QazCode (Beeline), чье спонсорство сыграло ключевую роль в продвижении этой инициативы. Мы благодарны за их доверие к нашему проекту, который был осуществлен без привлечения государственного бюджета или средств налогоплательщиков.

Мы искренне благодарим наших научных и административных партнеров, включая Министерство цифрового развития, инноваций и аэрокосмической промышленности Республики Казахстан, Министерство науки и высшего образования Республики Казахстан, АО «Национальные информационные технологии» (АО «НИТ»), Национальный научно-практический центр «Тіл-Қазына», Фонд устойчивых инноваций и технологий (SITF), Университет Максута Нарикбаева и Казахский национальный университет имени Аль-Фараби.

Также выражаем благодарность Назарбаев Университету, ведущему исследовательскому учреждению мирового уровня, чья приверженность поддержке инноваций и созданию среды для интеллектуального роста послужила важным фактором успеха этой инициативы.
Для нас это только начало захватывающего и сложного пути. Этот этап демонстрирует потенциал Казахстана активно участвовать в глобальной гонке ИИ, используя таланты и интеллект отечественных специалистов. В дальнейшем, продолжая привлекать средства для исследований, мы сосредоточимся на разработке передовых ИИ-моделей, которые отвечают потребностям населения Казахстана.
В перспективе мы планируем развивать модели следующего поколения, которые интегрируют языковые и визуальные данные, что позволит еще больше улучшить возможности ИИ. Мы также рассматриваем возможности поддержки модели других тюркских языков, опираясь на накопленный опыт работы с казахским и турецким языками. Таким образом, мы сможем еще больше укрепить связи между тюркоязычными сообществами с помощью передовых технологий и способствовать более широкому внедрению языков.
Кроме того, мы стремимся разрабатывать ИИ-продукты и услуги, которые принесут существенную пользу народу Казахстана и окажут значительное экономическое воздействие. В сотрудничестве с различными технологическими партнерами мы намерены сократить разрыв между наукой и промышленностью, стимулировать инновации и ускорять внедрение передовых научных достижений для поддержки роста и развития экономики страны.
Мы всегда открыты для сотрудничества и предложений дополнительной поддержки со стороны различных компаний и организаций.
Для получения дополнительной информации о проекте, запросов СМИ или предложений о сотрудничестве просим писать на электронный адрес issai@nu.edu.kz