
This material was prepared on the basis of questions provided by the Astana Plus editorial team.
February 14, 2026 — Astana, Kazakhstan — After recent questions about KazLLM model, the Institute of Smart Systems and Artificial Intelligence (ISSAI) has released new insights into KazLLM, Kazakhstan’s first large language model, explaining its purpose, origins, and strategic importance for the country’s digital future.
– Why do countries develop their own LLMs?
Generative AI and especially Large Language Models (LLMs) has become one of the most strategically important technological domains worldwide. LLMs are not just research tools, they are foundational digital infrastructure. They are used for search engines, education platforms, enterprise software, public services, national security systems, and next-generation productivity tools. Countries that develop and master foundational models are effectively shaping their future digital ecosystems, innovation capacity, and long-term economic competitiveness.
The scale of global investment clearly demonstrates this strategic importance. Major technology companies are allocating unprecedented resources to generative AI. Microsoft has invested over $13 billion in OpenAI. Amazon has committed up to $4 billion to Anthropic. Google continues to invest heavily in its Gemini models and AI infrastructure. OpenAI itself has announced plans to spend tens of billions of dollars on compute infrastructure, data centers, and model training in the coming years. These investments represent global-scale infrastructure and research commitments.
However, LLMs are not only about technological progress they are also about technological sovereignty. Countries increasingly recognize that relying solely on foreign AI systems creates strategic dependencies in data governance, language representation, security, economic value capture, and regulatory alignment.
As shown in the Table 1, many nations are therefore developing their own sovereign or nationally aligned models:
| Model | Country | Developer / Institution | Key Sovereign Feature |
| Falcon | UAE | Technology Innovation Institute (TII) | State-funded; among the first open-source models rivaling leading US systems. |
| WuDao 2.0 | China | Beijing Academy of AI (BAAI) | 1.75T parameters; supports national AI self-sufficiency strategy. |
| Fugaku-LLM | Japan | RIKEN / Tokyo Tech / Fujitsu | Trained on the Fugaku national supercomputer to avoid foreign cloud reliance. |
| TAIDE | Taiwan | National Science & Technology Council | Designed to ensure local data security and reduce external political bias. |
| SEA-LION | Singapore | AI Singapore | Engineered for Southeast Asian languages (Thai, Indonesian, Singlish). |
| GPT-NL | Netherlands | TNO / SURF / NFI | Transparent, GDPR-compliant Dutch model. |
| OpenGPT-X | Germany | Fraunhofer IAIS / Jülich | Part of Gaia-X ecosystem promoting EU data sovereignty. |
| GPT-SW3 | Sweden | AI Sweden / RISE / WASP | First large-scale generative model for Nordic languages. |
| Poro | Finland | TurkuNLP / Silo AI / LUMI | Trained on EU’s LUMI supercomputer; supports low-resource languages. |
| MarIA | Spain | Barcelona Supercomputing Center | Built using National Library web archives for cultural accuracy. |
| ALLaM | Saudi Arabia | SDAIA | Native Arabic model aligned with Vision 2030 objectives. |
| GigaChat | Russia | Sber | Domestic alternative to ChatGPT; compliant with local internet laws. |
| BharatGPT | India | IIT Bombay Consortium | Voice-first system supporting 14+ Indian languages and dialects. |
Table 1. Selected National Large Language Models and Their Sovereignty-Oriented Features
The pattern is clear: leading economies are treating LLMs as critical infrastructure. Developing domestic models allows countries to: preserve linguistic and cultural representation, ensure data security and regulatory compliance, retain economic value within national ecosystems, reduce geopolitical technological dependence, and build local AI talent and compute capacity.
In short, creating national or sovereign LLMs is a strategic decision about digital independence, economic resilience, and global competitiveness in the AI era.
– What is KazLLM and why was it created?
A large language model is an AI technology trained on vast amounts of text data to predict the next word in a sequence. When a person asks a question, it generates a contextually plausible response. Systems such as ChatGPT are built around this type of model.
A useful analogy is to think of a large language model as an engine. The engine itself is not the finished vehicle, but it is the core mechanism that enables everything else to function. The same engine can power different types of vehicles, for example, a SUV, car, tractor or minibus depending on how it is integrated and deployed. Similarly, KazLLM is the core technological component of AI assistants and chatbots. Applications such as government assistants, enterprise chatbots, or educational platforms can be built around it. In this sense, the model itself is the engine, while practical services require additional development, fine-tuning, integration with databases and tools, and large-scale deployment infrastructure. ISSAI was tasked specifically with creating this engine. We were not involved in building and/or operating end-user applications or services around it.
– Who is behind the creation of KazLLM? What is this team and why did they take on such a project?
KazLLM was developed by the Institute of Smart Systems and Artificial Intelligence (ISSAI) at Nazarbayev University between April 2024 and December 2024. The team is composed of young Kazakhstani researchers specializing in machine learning, data science, and computer engineering. The project was implemented in collaboration with key national partners, including the Ministry of AI and Digital Development, Ministry of Science and Higher Education, National Information Technologies JSC, the National Scientific and Practical Center “Til-Qazyna”, QazCode (Beeline), MIND Group (Maqsut Narikbayev University) as well as leading universities and research institutes.
One of the main goals of ISSAI was not only to create a model, but to build national expertise. Developing KazLLM required assembling high-quality datasets, designing training pipelines, conducting scientific research, and gaining practical experience in large-scale model development. These capabilities are essential for long-term technological independence.
ISSAI developed two versions of KazLLM: an 8-billion parameter model designed for workstation-level use and a 70-billion parameter model intended for deployment in data center environments. The model was based on Llama 3.1 architecture, because at that time it was one of the strongest open source architectures in the world. For instance, SEA-LION, a Southeast Asia-focused large language model released by AI Singapore in December 2024, was also based on Llama-family architectures. SEA-LION project is a big scale program and Singapore committed about US$52 million for this.
In most countries, big tech companies lead the development of generative AI models (OpenAI ChatGPT, Alibaba Qwen, Meta LLAMA, Anthropic Claude, DeepseekAI DeepSeek), however, in Kazakhstan, research and development (R&D) spending of the private sector as a percentage of GDP is relatively low and such activities are not usually undertaken by the private sector. That is why an academic research institute was approached by the government.
For the development of KazLLM, a private telecommunication company generously provided us access to the 8 NVIDIA DGX H100 nodes to do the training and a private fund provided us some budget to operate the team. In comparison, Meta used over 16 thousands of DGX H100 GPUs and more than 400 researchers contributed to create LLaMA, demonstrating that KazLLM was built with substantially more limited resources.
– What is the performance of KazLLM?
International practice is benchmarking these models. The ISSAI KazLLM model was evaluated based on standard commonly utilized benchmarks, which comprehensively assess model’s language understanding, problem-solving skills, factual knowledge, and general reasoning. Some of the benchmarks were adapted to the Kazakh language. The released KazLLM models outperformed the corresponding original versions of the Llama model on the aggregated metric. At the time of release (December 2024), the 70B KazLLM almost achieved the metrics shown by GPT-4o (Table 2 below).
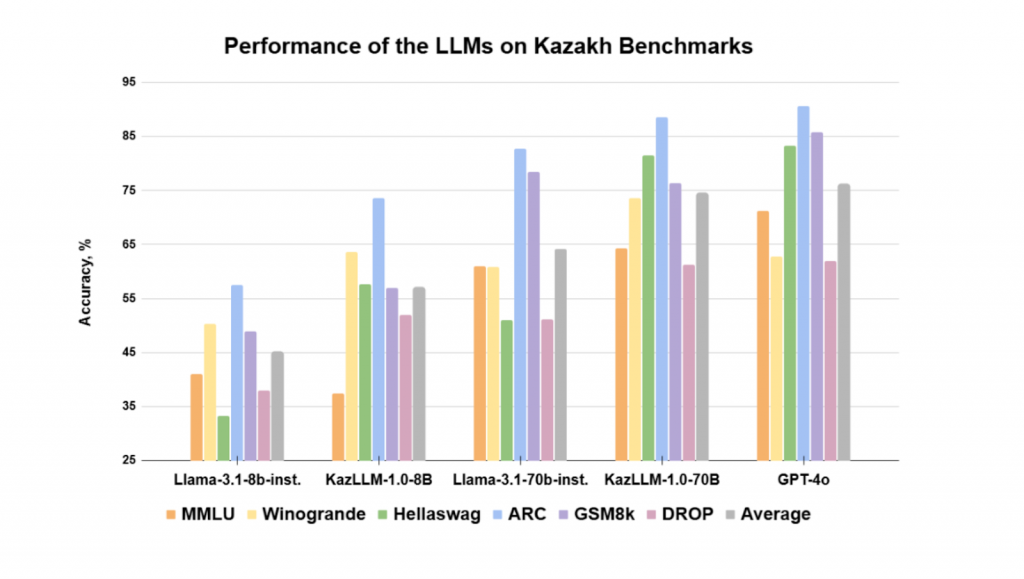
Table 2. Performance of the LLMs on Kazakh Benchmarks
However, AI is a race. New models are introduced roughly every six months and KazLLM should be further developed. We were not asked to develop KazLLM further after we transferred it to Astana Hub in December 2024.
KazLLM was created to ensure that Kazakhstan builds competence in generative AI, strengthens its research capacity, and develops the intellectual capital necessary to participate in this global technological transformation.
Moreover, the international leaders and experts noticed Kazakhstan’s effort to develop its own national KazLLM. Pioneering AI researcher Yann LeCun mentioned the performance of KazLLM in Paris Summit 2025. In the prestigious GSMA Foundry Excellence Awards 2025 event, KazLLM got an award.
– Why does Kazakhstan need its own language model?
ISSAI has consistently advocated for creating local solutions for the AI needs of Kazakhstan. However, the formal request to build KazLLM came from the government. As AI technologies increasingly influence public services, business operations, and information access, it became clear that relying solely on foreign solutions creates strategic dependence. Developing a local model ensures that Kazakhstan understands and can adapt the underlying technology.
– Many compare KazLLM to ChatGPT. What is the fundamental difference?
ChatGPT is a complete product and service ecosystem. It integrates multiple versions of large language models, intelligent routing systems, web search capabilities, databases, safety and moderation layers, and is deployed across massive global data center infrastructure. It is continuously updated based on user feedback and advances in AI research. Importantly, it is supported by extremely large financial investments. For instance, OpenAI’s annual operating and infrastructure costs are expected to reach around 1.4 trillion of dollars, reflecting the scale required to train and maintain such systems. This level of funding allows continuous model improvements and global deployment. KazLLM, in contrast, is a foundational model. It is the core AI engine, not a finished global product. To become a system comparable to ChatGPT, it would require integration with search tools and databases, development of a user-facing platform, continuous retraining, safety systems, and deployment in large-scale data centers.
Accordingly, all the developments outlined above necessitate substantial and sustained financial investment. A simple analogy is that KazLLM is the engine, while ChatGPT is the fully assembled and polished vehicle operating globally with continuous upgrades and maintenance.
– Who can use KazLLM?
KazLLM has been widely used for research purposes, as reflected in downloads from open repositories (https://huggingface.co/issai). Researchers and developers experiment with it as a foundation for further innovation. Since a non-exclusive license was transferred to Astana Hub in December 2024, we are not aware about its current operational or commercial deployment.
– How can these models simplify our daily lives?
A practical example would be interaction with government services. Instead of navigating complex websites, a citizen could describe their request in natural language and receive structured guidance (e.g. AI chatbot). In education, students could receive explanations of scientific concepts in Kazakh tailored to their level of understanding. In business, companies could automate document drafting or internal knowledge management. These applications demonstrate how generative AI can increase accessibility and efficiency.
– Why is it important for AI to understand the Kazakh language and local context?
Most global models are trained predominantly on English-language data. As a result, Kazakh language content and cultural context are underrepresented. This may lead to inaccuracies or superficial understanding of local realities. Furthermore, exclusive reliance on foreign AI systems creates technical and strategic dependence. Digital sovereignty requires the ability to understand, adapt, and, when necessary, independently develop technological systems, also it is important that models can provide trustable and correct information about local traditions, history and culture.
– What is the most common misconception about KazLLM and language models?
Continuous investment and research are necessary to remain competitive. That is why technologically advanced countries allocate a high percentage of their GDP to R&D (Israel, South Korea, Sweden, USA, etc.) and middle income countries which are rapidly developing also have above 1% of GDP R&D spending (while in Kazakhstan, it is around 0.2%).
A common misconception is that once a model is released, it represents a final or permanent achievement. In reality, generative AI evolves very rapidly. New architectures and training techniques appear frequently. Since the introduction of KazLLM, numerous advancements have occurred (mixture of expert architectures, reasoning models, multimodal LLMs, multitoken prediction, etc..). In the past 13 months, OpenAI has released about 5 major GPT model versions (including GPT-4.1, 4.5, and GPT-5 series updates), while Alibaba’s Qwen has released around 7 major model variants or families (including Qwen2.5 and Qwen3 series updates). A research and development team always needs to update the database, fine-tune the model with the latest architecture, and release new versions. This is very similar to the automotive industry but with a much faster time scale.
One of the most notable examples of private sector investment in generative AI in our region is the work of Sberbank (Russian Federation), which has been developing and deploying its own suite of AI models and tools. Sberbank’s generative AI offerings, such as GigaChat, are designed to rival global large‑language models and are being integrated across sectors, with plans to expand their capabilities and broaden access, including through open‑source releases of advanced models like GigaChat 3 Ultra Preview and other flagship AI systems.
Sberbank has also publicly stated aggressive investment plans in AI, committing to significant future spending in the sector with the aim of transforming its technological footprint and generating substantial returns from these technologies.
Given this precedent, and considering the Kazakh banking sector’s strong financial performance, there is a clear opportunity for Kazakh financial institutions to invest in domestic generative AI development, particularly with open‑source models that can be adapted and expanded locally. Such strategic investment could not only support technological sovereignty but also enhance competitiveness and innovation across the country’s digital economy.
– Is it possible for ordinary users to encounter KazLLM in daily life?
Yes, but large models require significant computational infrastructure. Training and deploying them at scale depends on high-performance data centers. Globally, there is intense competition to build such infrastructure. Without large-scale deployment, a foundational model cannot serve mass users effectively. Potentially, AI agents or chatbots developed around this model can be housed in new supercomputers in Kazakhstan (AlemCloud, Al-Farabium clusters). If the new supercomputers are not loaded with other important services and models then maybe models such as KazLLM can be deployed and open to the public such that user feedback can be collected.
– Can people see KazLLM in action today?
NU transferred a non-exclusive license to Astana Hub at the end of December 2024. Deployment depends on infrastructure and operational decisions made by the license holder. For current implementation details, we do not have information on that.
– How concerns about hallucinations and errors can be addressed?
All generative models can produce inaccurate responses. Mitigation requires integrating verification mechanisms such as database retrieval, web search, guardrails and user feedback systems. A standalone model does not guarantee reliability. Responsible deployment requires building a comprehensive product around it.
After generative AI models are deployed, their interaction with users becomes a critical source of insight. Every question asked, task attempted, or response rated by users provides valuable data about how the model performs in real-world scenarios. This interaction is continuously monitored, analyzed, and fed back into the product development cycle to identify patterns of errors, gaps in knowledge, or areas where the model’s reasoning falls short.
Commercial services built on these models rely on this feedback loop to update and refine model behavior, improve response accuracy, and enhance user experience. For example, adjustments may include retraining certain components, tuning parameters, improving prompt structures, or adding verification mechanisms like database retrieval and web search.
However, this process is labor-intensive and requires human, computational and financial resources. Skilled teams of engineers, data scientists, data curators, and product managers must review user interactions, classify errors, prioritize improvements, and implement updates. Additionally, human oversight ensures ethical and safe model usage, maintains compliance with regulatory requirements, and aligns outputs with business and societal standards. Without dedicated human intervention, models cannot reliably evolve to meet practical deployment needs or maintain the quality required for commercial services.
– How will such technologies affect education and the labor market?
Generative AI will reshape many professions by automating routine cognitive tasks. Countries that develop internal expertise are more likely to benefit economically. Those that rely entirely on external systems may experience greater disruption.
– Are there areas where using language models is dangerous?
There are both long-term and medium-term risks. Prominent experts, including Turing Award Winner Geoffrey Hinton, have warned about potential existential risks from advanced AI systems. Historian Yuval Noah Harari has similarly cautioned that AI could be more dangerous than nuclear weapons because, unlike atomic bombs, advanced AI can act autonomously and make decisions without human control. While the long-term existential and societal risks of AI require serious governance and oversight, there are significant medium-term risks such as deepfakes, misinformation, cybercrime, and most importantly technological stagnation. Countries and institutions that fail to responsibly develop and master AI technologies may lose competitiveness, technological sovereignty, and strategic influence in an increasingly AI-driven world.
– How can ordinary citizens contribute?
The current paradigm of AI is machine learning. In this paradigm, models learn from the data. If a Kazakhstani person generates public data (e.g., a Wikipedia article) in Kazakh language, local and global AI models will use this data to train and will know more about Kazakhstan and Kazakh language. Therefore, the regular citizen who wants to help can generate content that is relevant to Kazakhstan. Secondly, many tech giants provide models at low or no cost not because they are philanthropic organizations but because they want to collect feedback and real-world use cases. Therefore, using local AI models (Oylan, MangiSoz) and providing feedback would be an excellent contribution.